
並列処理動作に関する問題について、いくつかの例をあげてみます
1.割り込み処理の例
通常の組み込みソフトでは割り込み処理が多く使われますが、割り込み動作でも並列処理と同じ問題が起きることがあります。

この図の動作を説明します。
ここで問題となるのは、途中まで動いていた子関数(functionS) が同時に2つ動作中となり、先に動いていた処理が後の処理に追い抜かれて、その後再開することです。
この子関数(functionS)が以下のような処理であった時、どうなるでしょうか。
int functionS( int i )
{
x = a + i;
y = b + i;
return x + y;
}
a = 10, b = 20 であったとして、考えてみましょう。
通常の処理関数(function1) からの呼出しが functionS( 1 ) で、割り込み処理関数(interrupt1)からの呼出しが functionS( 2 ) だとします。途中で割り込みが入ったとする動作を示します。

図のように、通常関数からの戻り値は32になるはずですが、34になってしまいます。
この例の、functionS関数は再入可能な構造ではないので、誤った戻り値を返しますが、 x と y の変数をオート変数に変更することで再入可能となり、同じように割り込み処理が動作しても正しい結果が得られます。また、functionS関数の一連の処理を割り込み禁止状態にすることでも回避できます。
int functionS( int i )
{
int x, y; // オート変数は関数動作毎に固有の領域に確保(複数動作時は別領域)される
x = a + i;
y = b + i;
return x + y;
}
共有変数の読み書きに排他処理を用いたとしても、関連する複数の変数を別々に排他処理すると、不整合な状態を作り出していまいます。

図において、「主情報」と「補足情報」がセットで意味を持つ情報である時、ひとつひとつの書き込み処理を排他処理したとしても、その間で別タスクから参照があれば、不整合な状態を参照することになります。
このような場合、2つの変数に対する書き込み処理区間をまとめて排他処理する必要があります。
また、このような場合、処理の内容によっては、参照側のタスクにも、2変数の参照処理間に書き込みが行われないよう排他処理が必要となることがあります。
2つのタスクが動いている時に、片方のタスクのWRITEした変数をもう片方のタスクがREADする例を考えます。複数回のWRITEとREADがあると、READしたタスクが得る値は同じとは限りません。
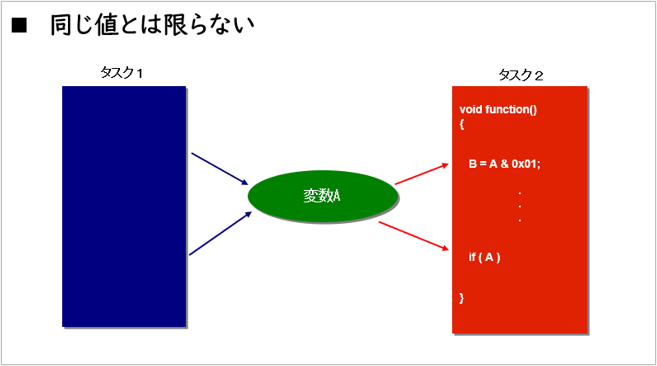
図のように、タスク1が複数回書き込む変数Aをタスク2の関数が2カ所でREADする時、その値は同じ値ではないかもしれません。その瞬間の値が必要であれば問題ありませんが、同じ値として処理したいのなら、一旦ローカル変数に移してから使用すべきです。
void function()
{
int X = A;
B = X & 0x01;
.
.
.
if ( X )
}
2つのタスクが動いている時に、片方のタスクのWRITEした変数をもう片方のタスクがREADする例を考えます。連続してWRITE・READするタスクのタイミングに違いがある時、データの読み飛ばしや重ね読みが発生します。
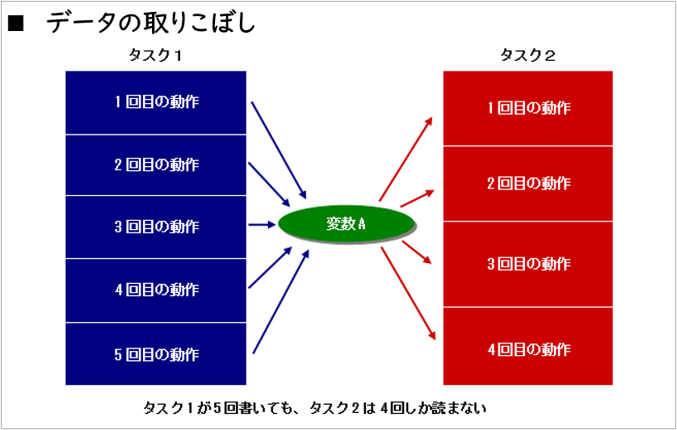
読み飛ばしや重ね読みが起きることを想定した処理を行う。または、同期を合わせる処理を挿入する必要があります。
ループ内で共有変数を参照する時、コンパイラの最適化の影響を受けることがあります。
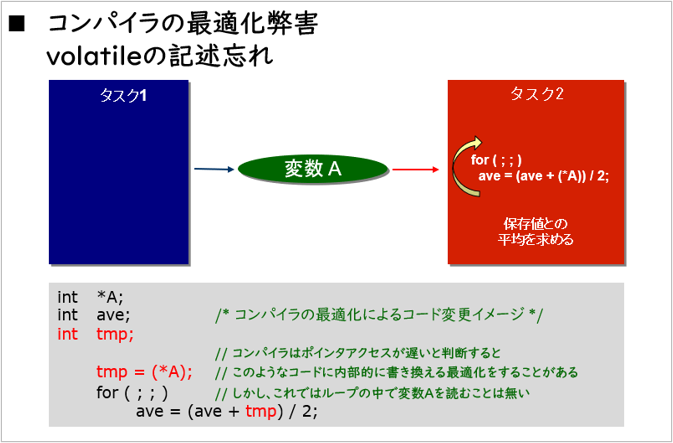
コンパイラはループ処理を高速化するために、影響のない範囲で、ループ内の変数アクセスや演算処理をループ外へ移動することがあります。実際にプログラムを変更するのではなく、コンパイル時に解釈を変えてコンパイルするようなイメージです。
しかしこのような最適化が行われてしまうと、ループ内で変数Aを読まなくなってしまいます。これを回避するためには、変数Aが volatile(揮発性:代入しなくても値が変わる)属性であることを示す必要があります。

これと似た例として、タイマレジスタ情報を上位・下位に分けて読み込む際にHI → LO → HIと読んで上位の桁上りを確認することがあります。このような場合にも、コンパイラの最適化により最後のHIデータを実際には読まずに最初のHIデータの値で処理されてしまうような問題もあり、この場合もvolatile記述で回避できます。
なお、本例のように前回値を扱う処理で見落としがちなのが、変数 ave の初期値への配慮です。
ループ内で前回の値との平均を求めていますが、初回のループでは前回の値が保存されてないので平均値が得られません。このような処理では変数の初期値に気を付ける必要があります。

コメントをお書きください