
パイプライン並列化の動作はとても時間がかかりました。
課題のプログラムは、"逐次処理"では約50秒で動作します。
"データ分割並列化" と "ジョブ(タスク)並列化"での動作は、どちらも逐次処理の処理時間を短縮しました。しかし、"パイプライン並列化"の最初の処理時間は、なんと約18時間半でした。
構造が複雑なので、多少の時間がかかるのは仕方ないかもしれませんが、想像もしてなかった遅さです。同じ処理にこれだけの時間をかけることができるのは、ある種の才能かと思うほどです。
そして、動作結果として検出したデータは正しいので、正しく動作しているように見えます。
このプログラムを何とか改善しようと思いましたが、方法が判りません。
とりあえず、プログラムのボトルネックを見つけるための常套手段と思われるプロファイルを取ってみました。
gccでは、コンパイル時に -pg等のオプションを指定することでプログラム実行時にプロファイリングデータが取れるようになります。プロファイル情報を見ることで、関数毎の動作時間の割合や動作回数が判ります。
ただし、プロファイル測定モードの動作には時間がかかるので、18時間半ものプログラムを測定するのは難しく、一部の区間データを切り出して測定しました。
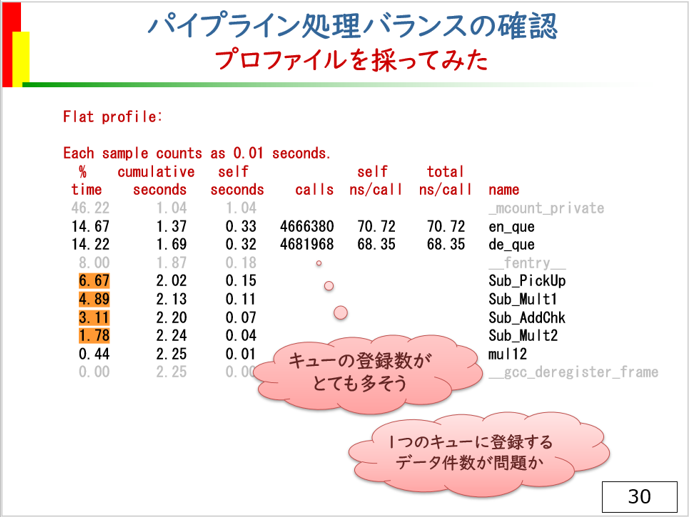
プロファイル結果はこのよう生成されます。
EMC組み込みマルチコアサミット2020、セミナー資料より
情報を示すタイトル部分を赤字にしています。
time の列は関数が動作した時間の割合(%)を示します。 calls は呼び出された回数。 name は関数名です。パイプラインを構成する4つの関数はSub_で始まる4つの関数で、時間をオレンジ色でマークしています。
マーク箇所をみると、4つのパイプライン処理関数の動作割合がそれほどバランス良く動いてるようには見えません。
4つのパイプライン関数は、main関数からスレッドとして起動されるので直接呼び出されることは無く、呼び出し回数が示されませんが、en_queとde_queの呼び出し回数が非常に大きな値になっています。
この2つの関数は、パイプライン処理関数がキューの登録・取出しをする際に使用する関数であり、キューアクセスの回数が多いことが判ります。
少し話がそれますが、この測定処理中に不思議な不具合を見つけました。
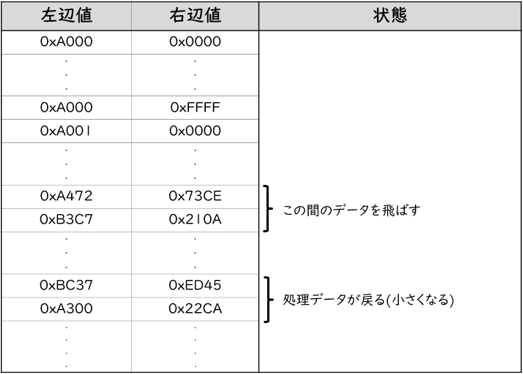
全データを扱う処理が18時間以上かかるのでデータの範囲を区切り、その動作状況を見るために処理データのログをとると、一部の区間を飛ばしたり、2度繰り返して処理する区間がありました。
例えば以下のような状況です。
0xA000×0x0000~0xBFFF×0xFFFFの範囲で評価した例
この不具合の原因は排他処理の誤りにありました。
一部のミューテックス変数の初期化処理が洩れており、排他処理が正常に動作していませんでした。
このような不具合があっても、43億件のデータから6件のデータを探すような処理ではその不具合はほぼ発生しません。今回のように区間データ処理が正常に動作することを確認するためにログを取らなければ不具合には気付かなかったでしょう。
実は、この不具合はミューテックスロック処理でエラーが発生していたのですが、ロック処理のリターンコードを見ていなかったために気付きませんでした。 なお、この不具合を改善した後も、18時間半の処理時間は変わらずです。
本題に戻ります。
プロファイリング情報で得た性能改善のヒントは、パイプライン処理のバランス問題とキューアクセス回数の多さでした。
どちらも、性能改善に関係すると思いますが、パイプライン処理バランスの改善は関数の処理内容を処理間で移動させ調整する必要があり、移動できない処理もあって簡単ではありません。
また、仮にこの4つのバランスを改善して均等化できたとしても、数倍の速度改善が望める程度だろうと考えます。もし、10倍の速度になったとしても、まだ2時間程度の時間がかかりそうです。

次回は、パイプライン処理の不均等ついての話とキューアクセス回数改善について説明します。

コメントをお書きください